引子
开学的专业实习,我选定的题目是学者信息问答系统。因为它符合将来的研究方向,也能作为一个功能加入到当前导师开发的微信小程序中。
很可惜,虽然富于研究价值,但由于遇到了需要标注大量数据、功能不够实用等问题,半途中要改变选题,因此在此做一个中期记录。
研究方案
需求
首先需要明确问答系统的需求。实现这个问答系统的目的,是可以针对学者的相关提问作出回答,例如学者的学历、毕业学校、研究兴趣等等。
由于现有的答案生成模型效果一般,这一问答系统是根据问题,在答案库里找出答案,作为回答。
答案来源
在选题时,并没有学者信息的相关数据资源,因此答案均来源于网络。
有两种爬取数据的方法:
- 针对某一学者信息网站,编写特定的爬取器,可以获得结构化学者数据
- 按照搜索引擎的返回结果进行爬取,需要编写筛选器找出学者的相关信息
我首先实现的是第二种,因为更具一般性,而前者可以作为后者的补充。
答案匹配的基本思路
简单的答案匹配模型一般是一个神经网络,输入问句和答句,输出匹配程度。
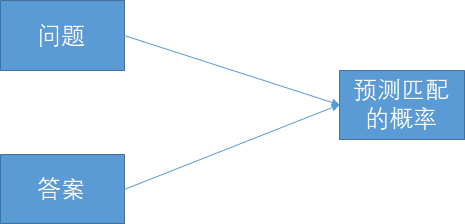
由于数据有限(需要自己准备数据,且很难迁移学习),我预计匹配的效果不会很好。
同时,我注意到关于学者的问题多数都围绕着学历、职称、研究方向等简历上的常见信息。这类问题可以单独处理:预先针对常见问题,训练提取器,从学者的介绍文本中提取数据,保存在数据库中。回答问题时,判断问题是否属于这类问题的某一类别,是的话直接从数据库中给出答案。
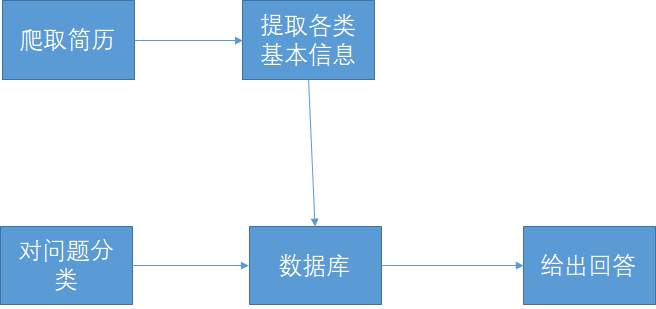
综上,答案匹配的过程如下:
- 判断问句是否在询问常见信息
- 若是,判断问题的类别,利用数据库中的数据给出答案。如果数据库中没有数据,则通过搜索引擎爬取简历,再利用筛选器找出常见信息。
- 若否,利用搜索引擎搜索问句,将结果中的句子与问题一一比对,找到最匹配的句子作为答案。
任务清单
经过以上分析,需要完成的组件挺多的,列举如下:
- 网页爬取器
- 正文提取器
- 简历筛选器:判断文本是否为简历
- 多个基本信息提取器,从文本中提取职称、毕业学校、研究方向等简历中常提到、用户常问到的信息
- 答案匹配模型,我想先试试这个
研究过程
网页爬取
利用了google custom search api,每天有1000个免费请求。这个api是针对特定网站进行搜索的,但可以加入全网的搜索结果,曲线救国。
正文提取
存在着提取网页正文的库,我尝试了三个:
- boiler pipe
- goose3
- 行列布局提取
效果都不好,因为网页中包含的是简历,与一般的文章不同,最后自己写了一个。
简历筛选器
我用“名字+学校”来搜索简历。研究过程中发现,排在前面的搜索结果也可能包含新闻等其他内容,需要进行筛选。
得到分类器的过程如下:
- 从训练集中提取高频词
- 计算每份文本的高频词在训练集中的TfIdf值,作为其特征
- 拟合逻辑回归模型
可以参考这篇文章。
数据集是我自己分的。为了提高标注效率,不看花眼,还写了一个标注器。(事实上,一共写了三个标注器。)标注器采用简单的tkinter框架,写起来方便,但感觉接口设计和文档都比较简陋。
基本信息提取器
我是以“硕士毕业学校”为切入点进行研究。后来才发现不少老师没有硕士毕业学校,因为是直博的。。。
首先想到的模型是,输入一串词,输出硕士毕业学校的起止位置。但一个句子里可能会出现多次答案,产生干扰,模型的注意力也可能分散在学校名称上,但学校叫什么并不重要。我确定的提取思路是:先找出包含学校名称的句子,将学校名替换成一个符号,然后分词、向量化,送入分类器识别,判断符号是否代表了硕士毕业学校。
起初我想找一个学校清单,但没发现囊括了国内外高校的清单,而且这种罗列的方式虽然准确但难以推广、不够优美。我换用命名实体识别的办法,找出包含“学校”、“学院”、“研究所”字样的所有机构名,应该可以基本覆盖简历中出现的学校。
由于数据有限,我选择用简单的模型,和训练好的词向量。模型用的是CNN,窗口宽度与词向量等长,数据填0对齐。
接下来就是数据的问题,为此,我又写了一个标注器,标注了近1000个句子。。。更尴尬的是后来发现学校名是硕士毕业学校的仅不到30个。。。
我用类别权重来处理样本不平衡的问题,但由于正样本太少,正确在50%左右,需要找出更多正样本来改进结果。
以上,是我在学者信息问答系统课题中所做的工作,由于题目的改动,暂时不继续做了。
坑
最大的坑是jpype包的问题,在里面折腾了十多个小时吧。。。
我在调试从简历提取硕士学校的代码时,报告JVM只能启动一次的错误。我知道pyhanlp在import时会调用jpype.startJVM(),并误以为Stanfordnlp也依赖jpype(实际上不依赖,代码里是先启动了一个Java服务端进程,再用python代码与之通信),就尝试了以下的方法:
- 第二次启动JVM前先把它关掉。在函数中局部导入pyhanlp,在
import pyhanlp语句前执行jpype.shutdownJVM()。然而不行,jpype文档的说法是“Because of lack of JVM support, you cannot shutdown the JVM and then restart it.”???(介绍python导入的文章说,局部导入没用处,这里处理包冲突的时候不就用到了嘛) - 既然JVM关不掉,那就杀进程。我在新进程里执行用Stanfordnlp做ner的代码,然后把进程杀死。我先后试了multiprocessing包和subprocess包。由于不是Stanfordnlp和pyhanlp的冲突,自然都是没效果。。不过我相信杀进程的方案本身是可行的。另外,在用subprocess包时,子进程通过向管道写入pickle字符串来传递对象,但我在子进程层层调用的某个函数里打印了调试信息,破坏了pickle的字符串,调了一晚上。。。吃一堑长一智吧。
- 杀进程没成功,我又翻到了
jpype.addClassPath()这个方法。那么可以修改pyhanlp的初始化代码(虽然改包的代码很不优美),加入判断,如果JVM已启动,就将所需的jar包直接加到class path里。但仍报ClassNotFoundException。查了一下,Java里动态修改class path需要用到反射,且要安全管理器允许,是很tricky的方法。而网上很少有人提及jpype.addClassPath()。
最后我发现和pyhanlp冲突的是之前用来尝试提取正文,import语句已经变灰的boilerpipe,删掉就好了。。。
感想
这个课题前后做了一个月,其实真正研究的时间除去国庆,剩下时间也只利用了一半吧。一直觉得近期我没有很好地利用这些空闲时间,要努力做些以前想做未做、有意义的事。
完成这个课题的过程让我对问答系统有了基本的了解,熟悉了分词、命名实体识别、词向量等nlp的基本操作,接触了standfordnlp、jieba、pyhanlp、nltk等工具包。python编程方面也练了不少,多进程、tkinter、jpype等等。另外,我尝试使用virtualenv来管理python项目,它使代码和依赖包都集中在一起,不受干扰、方便移植。
我想,做这些课题,最有价值的是调研各个环节、针对具体情况设计研究方案,并解决落实方案中遇到的困难的过程,还有编程能力的一些锻炼。
接下来是调好基本信息提取器和实现、调试答案匹配模型的工作,很有意思,可惜课题在此要暂停了。
我还想吐槽一下python。调试器在计算表达式时可能会卡住、崩溃,对象也可能有动态属性,夹杂在一堆下划线的内部变量里,看得辛苦。作为动态类型语言,不用声明类型,脑子里却要关注着变量是什么类型,有哪些属性、方法,IDE常常推导不出来。没有类型声明,函数的参数、返回值也很迷,常要看文档、看代码,不像Java能见名见类型知义。pip等包管理器也不可靠,不时报错。而实际上,许多模块都是C++、Java写的,留给python的是简陋的接口和文档。“胶水语言”实在有几分贬义,表面的简单是以牺牲工程能力为代价的,不是能做胶水,而是某种意义上只能做胶水。可能是我没领悟到python思想,再多写写可能会适应吧。。