最近,我在合作实现一个有美肤、瘦脸功能的美颜滤镜,作为数字图像处理课程的大作业。我负责美肤部分,这几天设计、实现了肤色检测、美白降噪的相关算法,自觉研究了些东西,就写了这篇笔记。
其中的美白降噪部分比较简单,只要调色、滤波就可以了,剩下的是用经验、技巧来改善效果。这篇文章以论述肤色检测为主,课题的其他部分也会有所涉及。
现有的肤色检测算法
目前的肤色检测算法有这几类:
- 简单阈值法。例如,在RGB颜色空间中划分出皮肤颜色的阈值,或者排除亮度分量,如在YCrCb空间中对Cr、Cb进行筛选。
- 自适应阈值法。例如,在YCrCb空间,对Cr分量做OTSU分割,因为一个人肤色的颜色范围不大嘛。
- 颜色建模法。这是对颜色更进阶的筛选。例如,椭圆模型,因为肤色的Cr、Cb分布图像接近椭圆,把Cr、Cb坐标落入经验椭圆内的像素判定为肤色像素。还有课堂上提到的高斯模型,其实它的分界和椭圆模型是非常接近的。理论上,也可以做更复杂的假设,用更强的模型,但对于颜色特征来说,可能没必要,容易过拟合。
- 特征更丰富的复杂模型。除了一个点颜色值,也可以用一个区域、甚至整幅图像的像素,引入形态学特征、纹理特征等等,这变为一个机器学习问题。
前三类方法出现得比较多,它们的比较可以参见这篇文章。用得多是由肤色检测的应用性质决定的,通常对检测的速度要求比较高,甚至需要用于视频实时检测。而对于美颜滤镜这类应用,对精度没有特别高的要求,因为肤色美化是柔和的,被美化区域的边界是羽化的。
当然,在控制算法复杂度的前提下,肤色检测越准越好。现有的算法准确度是很一般的,那篇对比文章里的效果经过了针对性的参数调整,如果在光照、肤色、拍摄器材各异的现实场景中,将很难找到精准定位皮肤区域又不引入噪声的通用经验模型。
下图为Cr、Cb阈值法的皮肤检测结果:

Cr、Cb阈值法对不同人种的肤色是适用的:
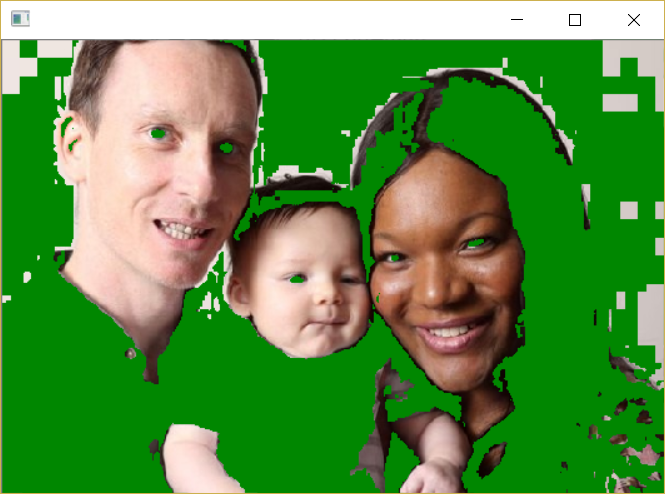
但也意味着当背景位于这个较大的肤色范围时,效果的不理想:

自适应的肤色检测模型
现有的肤色检测模型存在着肤色检测范围和背景色误判的矛盾。但对于同一个人来说,他的肤色范围相比人类全体狭窄了很多,如果能针对他的肤色建模,再做筛选,有望大幅提升准确度。
我们所做的美颜滤镜刚好提供了这一思路的必要条件:美颜滤镜需要用到人脸检测,那么肤色检测模型可以利用人脸像素建模。
即先对照片做人脸检测,检测结果既用于瘦脸,也用肤色建模,这就在不增加计算成本的情况下,提升了肤色检测的精度。
单人肤色模型的选择
由于面部像素的数量有限(样本少),而且需要对照片的所有人脸分别建模和检测(计算复杂度不能太高),这就要求一个简单的单人肤色模型。
其实,我还有一种思路:收集大量的肤色样本去训练一个较复杂的模型,它以单人的面部像素特征作为输入,输出的是这个人的肤色分布。这种方法需要大样本集和对复杂模型的构建和调试,不是几天工作量的大作业了。
肤色是皮肤的固有性质,与亮度无关,通常在建模时会剔除亮度分量。当然,皮肤的光泽是体现在亮度里的,这里就忽略了。下面是我在YCrCb空间对Cr、Cb分量所作的热力图:
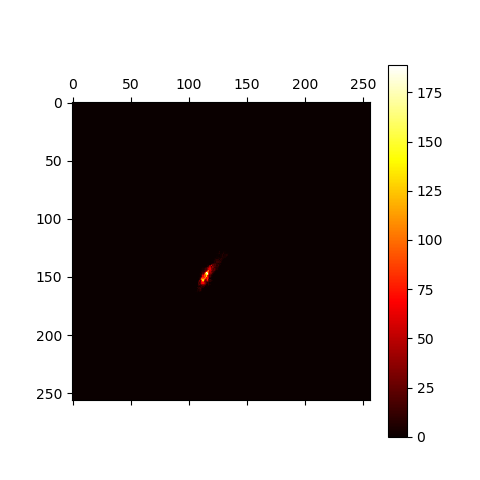
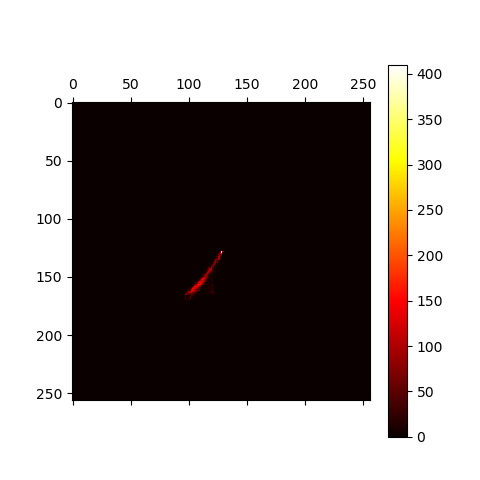
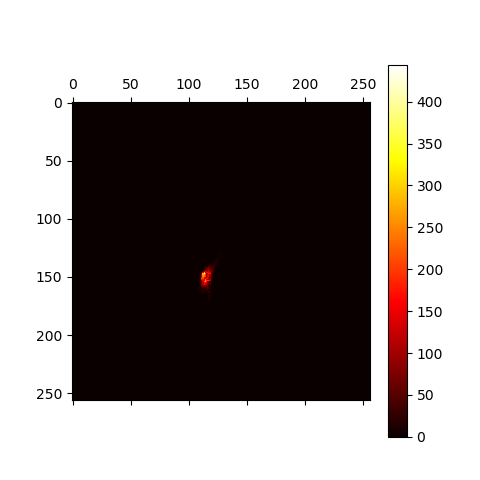
可以看到,Cr、Cb分量坐标点的聚集比较紧密,我选择用高斯分布对单人肤色进行建模。
多元高斯分布的参数估计与概率计算
极大似然法的高斯分布参数估计式很直觉,就是样本的均值和协方差,即:
于是,我们得到了肤色Cr、Cb分量的高斯分布:,也就得到了Cr、Cb的概率密度,于是根据像素点的概率密度与分布中心点密度的相对关系估计是否为肤色。这样做比较启发式,既然使用了高斯模型,有没有更直观,可以从概率上解释的筛选准则呢?
有,这涉及到多元高斯分布的由来。
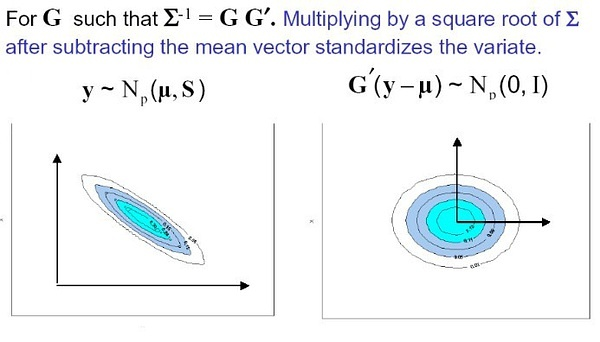 先忽略上图的那句话(它已经给出了答案),左图是一个一般的二元变量分布,简单地说(复杂的我也不会说。。),二元高斯分布的假设是:对样本坐标作平移和伸缩变换,使其均值落在原点,沿各个方向的标准差为1(即各分量的方差为1,分量间的协方差为0),此时样本坐标到原点的距离服从标准正态分布:
先忽略上图的那句话(它已经给出了答案),左图是一个一般的二元变量分布,简单地说(复杂的我也不会说。。),二元高斯分布的假设是:对样本坐标作平移和伸缩变换,使其均值落在原点,沿各个方向的标准差为1(即各分量的方差为1,分量间的协方差为0),此时样本坐标到原点的距离服从标准正态分布:
那么,对于一个待检测像素(Cr,Cb),只要根据得到的高斯分布模型的参数和,对它作坐标变换,然后求出到原点的距离,就可以参照标准正态分布的概率表了。
事实上,(Cr,Cb)坐标与距离的关系并不用推导,答案已经包含在多维高斯分布的概率密度函数中了。
标准正态分布的概率密度为:
其中公式前的系数使其积分为1。
多元高斯分布的概率密度为:
对比两式,按照多元高斯分布的定义,就是我们要找的距离的平方。我们寻找的坐标和距离的关系在得到多元高斯分布密度公式的过程中已经推导过了,具体的推导过程,可以参考这篇文章。
至于为什么归一化系数不一样,这里也解释一下。事实上,我们是根据解出多元高斯分布的概率密度公式,式中的在积分范围内是常数,因此两式的系数相差倍。这其实是上一段的前提,正因为只是系数的差别,我们才能从多元高斯分布的密度公式中看出坐标与距离的关系。
于是,我们的模型可以加入一个期望参数,我把它定义为:如果一个人肤色符合所建立的高斯模型,则他的肤色像素被包含在模型的筛选结果里的比例的期望为。
对应的筛选条件为:
这样就有了可以从概率角度解释的筛选标准。
肤色检测的实现细节
肤色检测算法的流程如下:
- 求取照片的缩略图。
- 根据面部特征点的检测结果,确定每张脸的像素范围。
- 对于每一张脸,在缩略图上求出脸部肤色的高斯分布作为此人肤色分布的估计,然后根据筛选标准,找出缩略图上所有符合该分布的像素作为此人的皮肤范围。
- 求图中所有人的皮肤范围并集,作为检测结果。
下面介绍几个实现的重点细节。
面部图像的提取:由于瘦脸部分需要对面部关键点做变形,所以面部图像就是面部关键点的凸包。
1 | # 求面部特征点的凸包,得到面部掩模 |
由于面部图像往往有五官、头发等,我先用较宽松的Cr、Cb阈值做了过滤,然后再剔除距离均值最远的5%的离群像素。
加速计算:对原图做提取的速度是很慢的,也没有必要那么精细,我对图像做了两次pyrDown()操作,在1/16的缩略图上做肤色提取。
肤色检测时,需要判断(Cr,Cb)坐标是否满足不等式约束,涉及矩阵计算,比较耗时。而坐标组合只有种,因此可以用缓存优化。
皮肤检测的形态学优化:检测得到的掩模偶尔有细小颗粒,但皮肤是不会有细小孔洞的,可以用图像的闭运算去除。
1 | # 形态学闭运算,消除掩模的细小孔洞 |
自适应肤色高斯模型的效果
讨论完理论部分,可以来看看模型的效果了。
下面是单人的肤色检测结果(在1/16的缩略图上执行以加速计算):




多人的检测结果是对单人的皮肤区域求并集,如下:





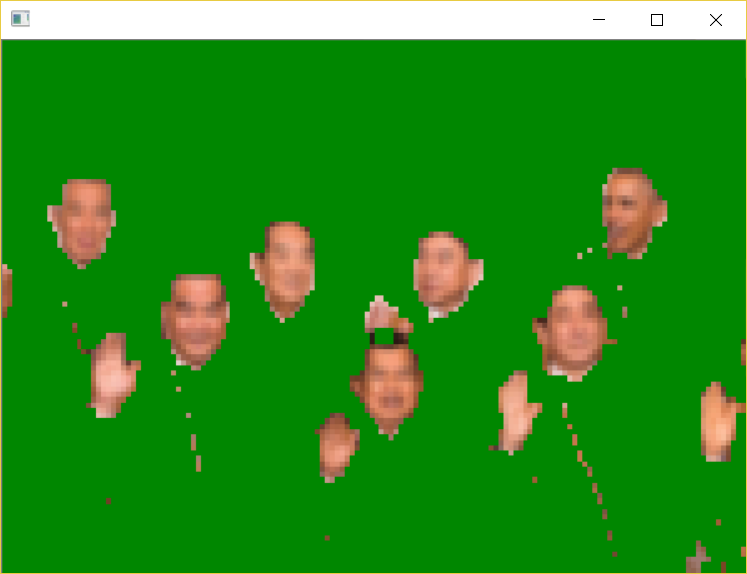
美肤算法
美肤算法包括磨皮和美白,更具体地说就是滤波和调色。这部分的算法比较简单常见,更多是依赖一些参数上的经验技巧。
我先对整张照片做滤波和调色,包括:
- 双边滤波
- 高斯滤波
- 在YCrCb空间对Y分量做基于幂函数的增强。相比倍数放大或者增加偏移量,幂函数增强不会因为数值溢出而需要做截断,影响对比度。
滤波和调色加入了强度参数,供用户调节。
然后依照掩模将处理图和原图拼合,一开始是这样的:

没错,要对掩模进行柔化,使美化的皮肤与其它部分平滑过渡,我对掩模做的是均值滤波,把两张图片按掩模权重混合。

对照一下原图:
肤色相差大的(幂函数曲线对肤色深的人的美白力度大):

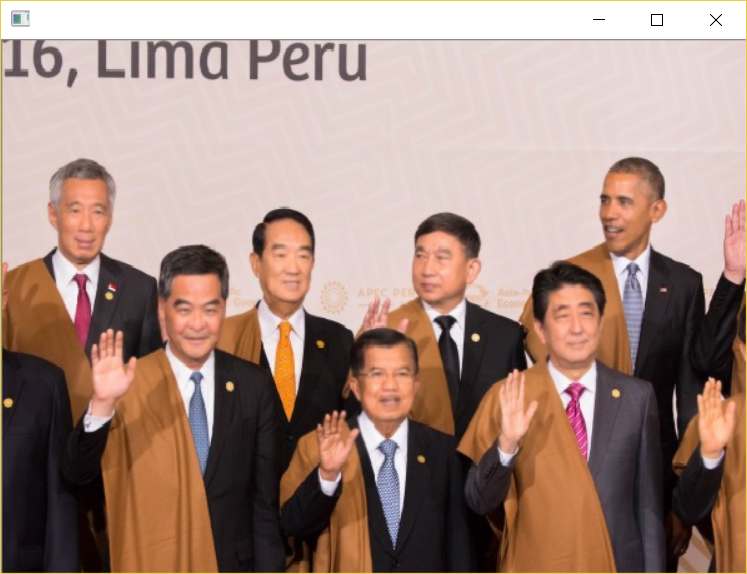
合照(准确美化皮肤区域):
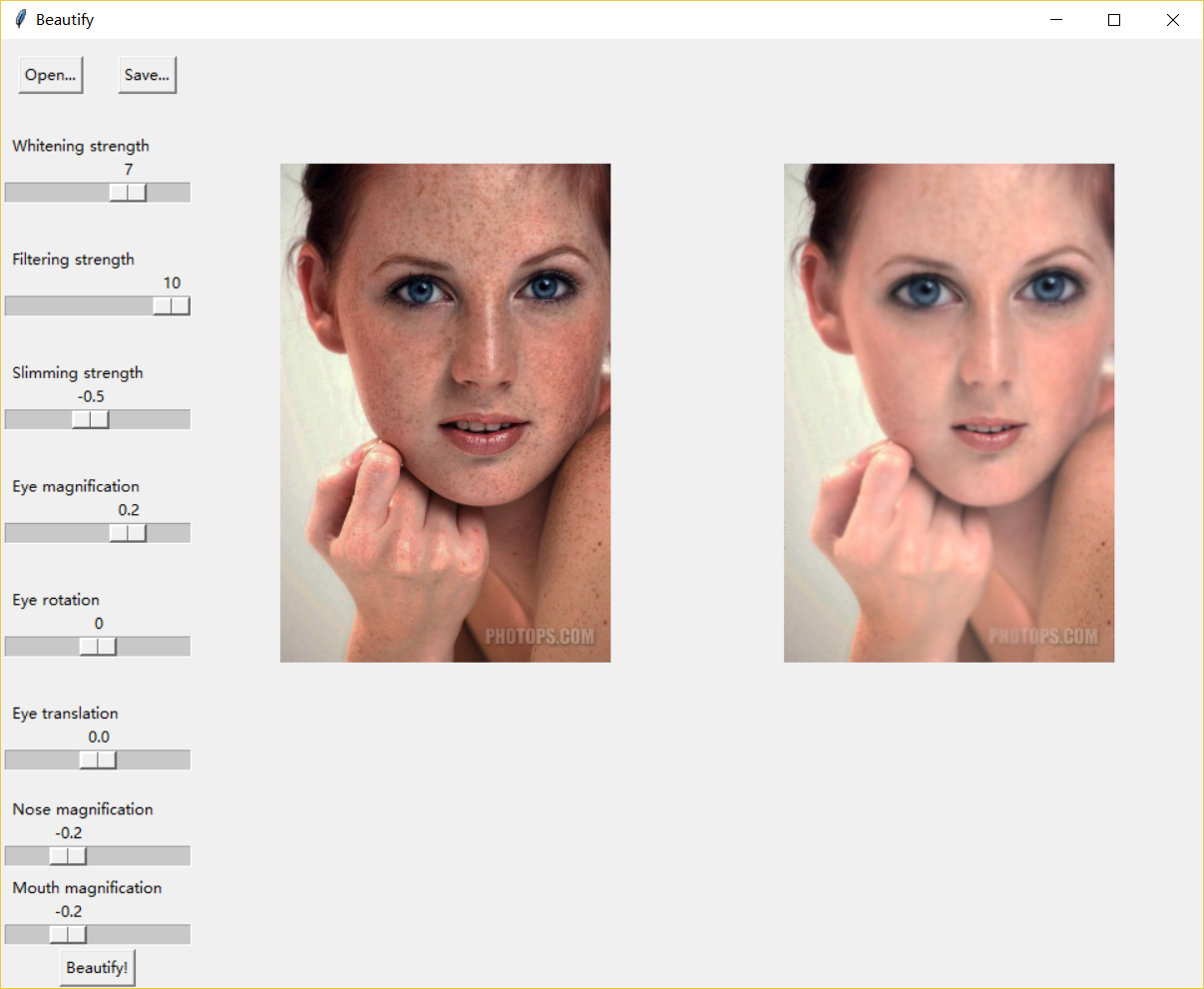
经典美肤对比图:

在肤色检测、美肤环节有各种阈值、卷积核等参数,我对照着几张样张做了简单的调整,体现出效果就好,毕竟关注点在算法上。
脸部变形算法
这部分不是我负责的,这里简述一下原理,毕竟我调了一个bug调到凌晨4点。。
脸部变形的流程如下:
- 提取脸部特征点。我们采用的是dlib库,真是又快又准,感觉我之前的闭眼检测课题也应该用这个。。
- 根据用户输入的参数对特征点做坐标变换。
- 基于变换前后的两组关键点做图像变换,我们利用的是opencv的TPS变换函数。
TPS变换时,只输入两组面部特征点是不够的,面部以外的图像也会出现扭曲,所以我们把脸外的一个矩形框上的点也加入特征点约束数组中,以保证图像的扭曲不会超出面部范围,但这也显著增加了特征点的数量,拖慢了计算速度。
下面是调bug的口水。。
我调的是只能变换图片中一张脸的bug。因为感觉改起来很简单(大不了分别对每张脸做一次变换嘛),写代码的同学说调不出来,就看了一下。。
首先我发现眼睛、鼻子等关键点坐标变换函数写错了,导致只能变换数组里第一张脸的坐标,懒得改那么多变换代码,就分别对每张脸的特征点做变换,一起加入特征点数组。
然而还是不行,带着bug已经调了99%的幻觉(Debug没有进度,只有调出来了和没调出来),我把代码左改右改,推翻了一个又一个猜想(特征点太多了?变换幅度太大?变换前后的特征点对不上导致无解?numpy数组的空间布局问题?),搜遍了资料(关于opencv TPS的文档和讨论很少),终于在第n次怀着“唉,再试最后一次吧”的想法验证猜想时找到了原因:
opencv TPS变换的关键点不能重复!它不会自动去重,也不会报错,也不在文档写明,也没人讨论,就返回一张空图让你猜原因!
完稿后的补充:我们所用的cv2.createThinPlateSplineShapeTransformer()是opencv的内部函数,不是为外部调用准备的。
UI的编写
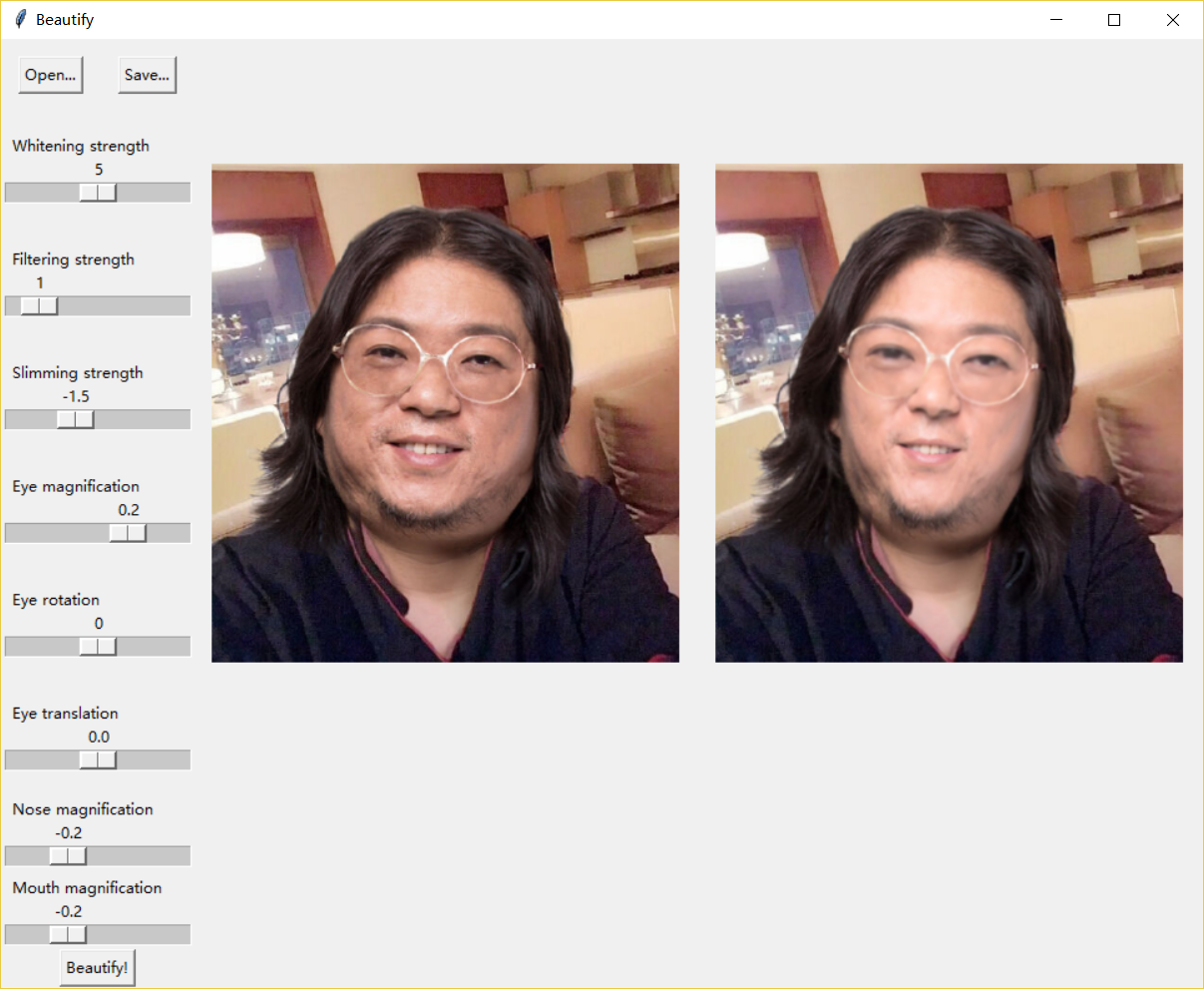
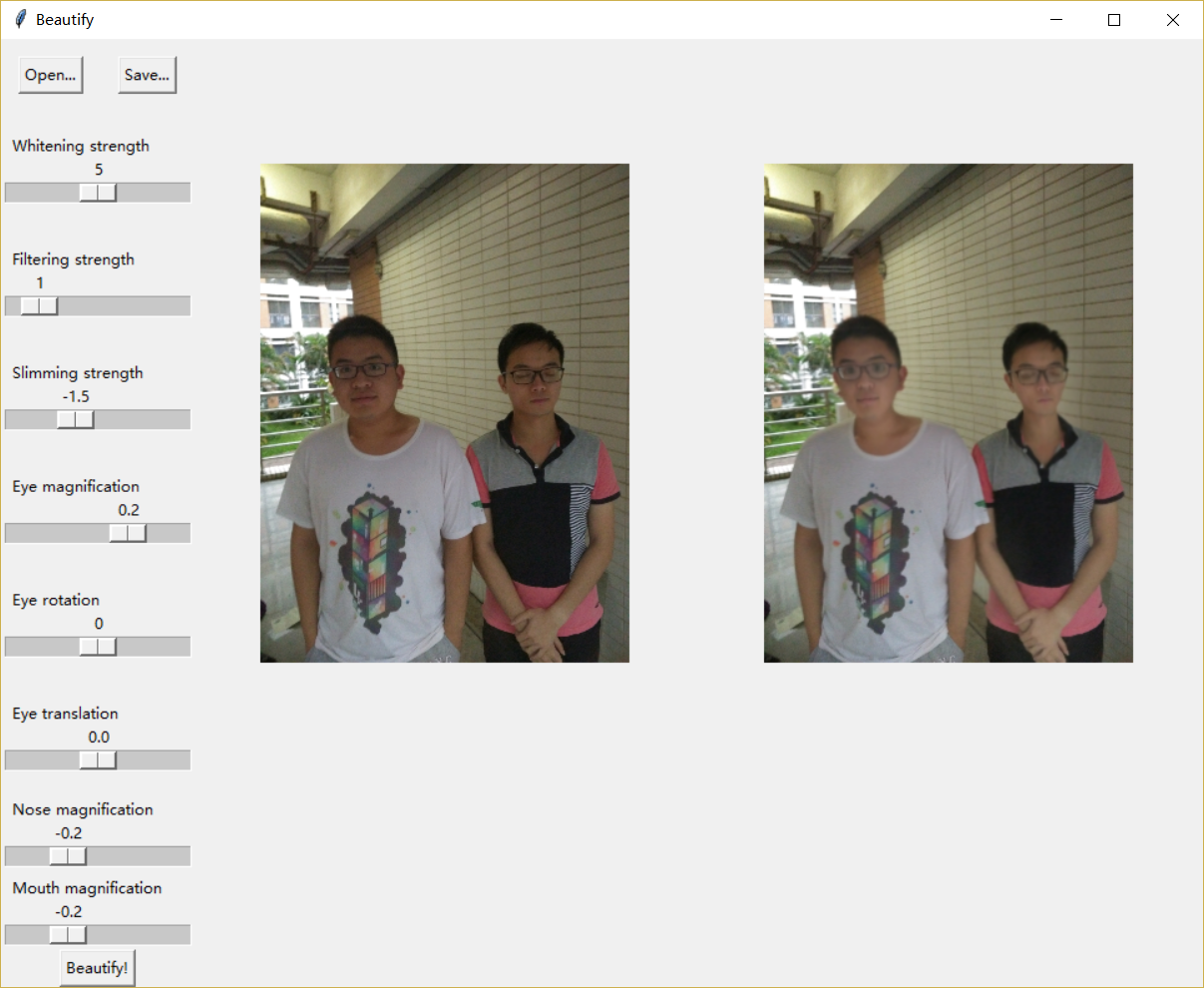
我用Tkinter框架编写了简单的演示UI。
为了加速计算,展示给用户的效果图是对缩略图的处理结果,保存时再处理原图。(脸部变形算法有点太耗时了。。处理原图要几分钟)
python项目打包
这部分介绍开发环境的打包和可执行程序的打包。
为了方便小组在不同电脑上开发,我们使用了venv虚拟环境,把所有依赖和代码都集成在虚拟环境中。然而,转移工程时还是遇到了问题。
经过摸索,在新电脑上用pycharm跑起开发环境的方法是:
- 安装对应的python版本(32位和64位也要区别开,因为很多很多依赖是C/C++写的)。
- 修改venv目录下的pyvenv.cfg,使home变量指向对应的python解释器。
- 有可能需要配置pycharm项目设置里的python解释器路径。
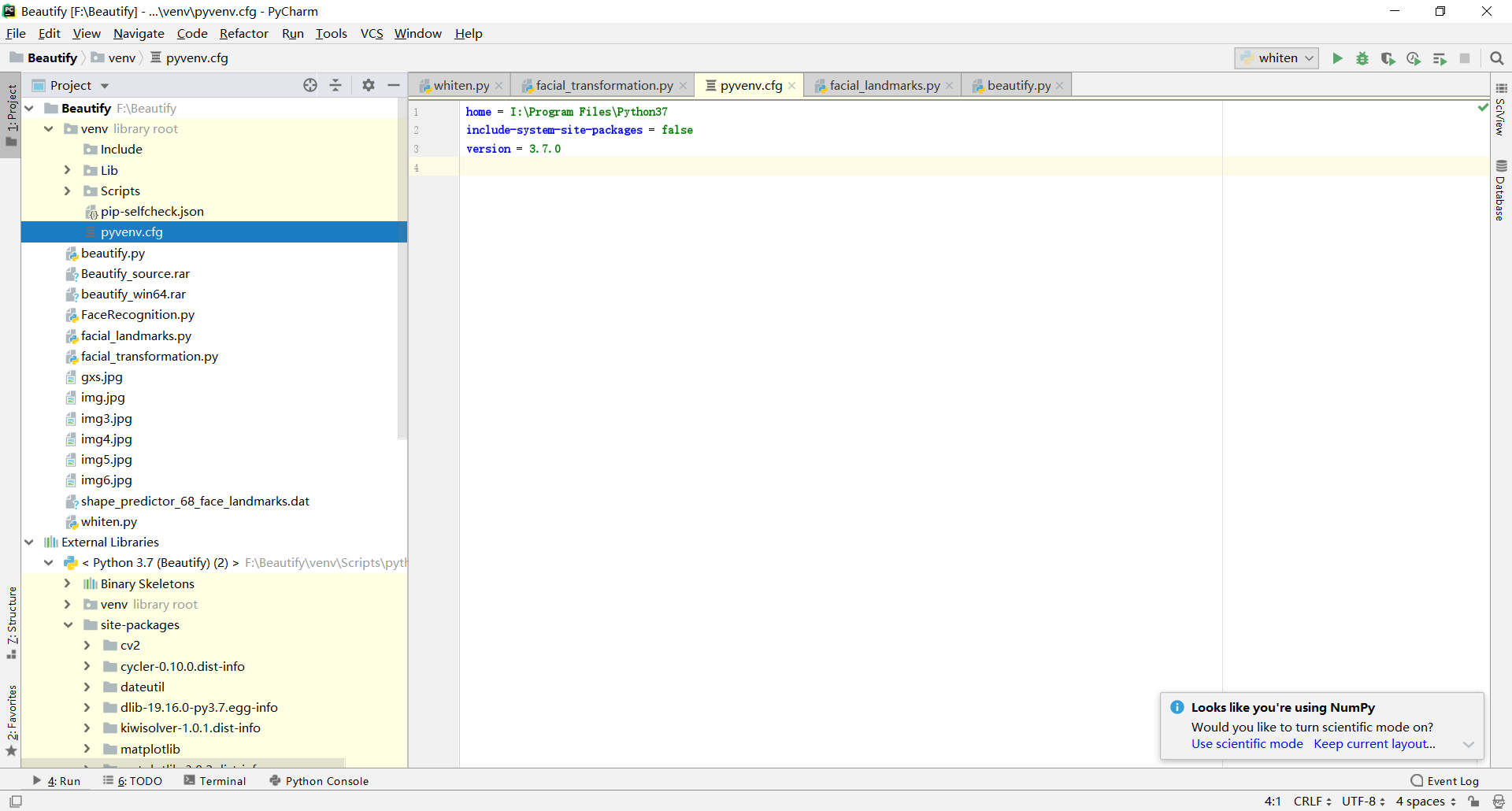
这种方法能让pycharm识别虚拟环境、运行程序,但在虚拟环境内依赖的安装、以及可执行程序的打包都可能遇到问题(我就遇到了。。)。
事实上,虚拟环境是用来隔离一台电脑上的不同项目对python解释器和包的依赖的,它们不是为了方便不同电脑间的项目迁移而设计的。
正确的迁移姿势应该是复制源码并导出依赖,即requirements.txt,然后在新电脑上搭建环境。如果有网络问题,可选择国内镜像或者离线安装。环境迁移的讨论可以参考这篇文章。如果要部署到生产环境,也可以使用docker容器。
我使用pyinstaller进行可执行程序的打包,可以参考这篇文章。
如果要打包其它文件(自己的pyd、模型权重、图片等等),可以在pyinstaller参数中指明。更简单的方法是直接复制到打包生成的文件夹里,因为可执行程序的工作目录就在那里。但如果选择生成单个exe的话,用参数指定的额外文件的位置需要在运行时获取,详见这里。
体会
若干个python项目做下来,对python的包管理要有心理阴影了。原因大概根植于python的胶水语言定位,大量依赖是用C/C++编写的,安装时需要在用户的电脑上编译,这就要配置各种编译环境,导致安装过程容易出现意外错误。cpython的各个版本也不全兼容,项目的依赖包耦合于开发者的cpu架构、操作系统、python版本、甚至环境变量,导致迁移困难、安装费劲。听说conda的包管理集成了编译工具链,尽管更笨重,也没解决环境迁移问题,但简化了依赖的安装过程,值得尝试。
不过,python代码越写越顺了,numpy的语法糖挺甜的,但我有点怕有坑,会在调试时看看是不是按自己想象的那样执行。。
最后,针对具体问题,设计、实现自己的算法真是非常有趣。巧妙的思路会让我兴奋,实现算法也和写网站的公式代码不同,每行代码背后都体现着自己的想法。当然,算法实现离不开工程的优化,而编写有创意的程序也一样有趣。